
 As a longtime lover of source control, I've been known to have a few opinions on how to use it. I've generally taken the approach that the tool I use needs to work for me, not against me. Unfortunately with the flexibility of a distributed version control system, such as Git, the right answer isn't always obvious. Taking the time to impose some arbitrary constraints on your workflow will make your daily tasks more predictable, and therefore easier to complete. One of the biggest wins you can make is using a standardized branching pattern for your work. If your team hasn't already "unvented" its own best practices, this article will help you choose an effective workflow for your team.
As a longtime lover of source control, I've been known to have a few opinions on how to use it. I've generally taken the approach that the tool I use needs to work for me, not against me. Unfortunately with the flexibility of a distributed version control system, such as Git, the right answer isn't always obvious. Taking the time to impose some arbitrary constraints on your workflow will make your daily tasks more predictable, and therefore easier to complete. One of the biggest wins you can make is using a standardized branching pattern for your work. If your team hasn't already "unvented" its own best practices, this article will help you choose an effective workflow for your team.
The different workflows really break down into two simple categories: the first is best described as a scheduled release pattern; the second as continuous deployment. Of course there are a spectrum of options in between, but let's look at the polar opposites for now.
The first option, the scheduled release, is typically used for products which have launch dates and different versions available at any one point in time. For example, Drupal uses a major.minor syntax for its releases. In some scheduled releases, you will also have a smaller “hotfix” release which adds a third set of numbers to the released version. From a branch perspective, this means you have a number of parallel development branches at work. Each time you begin new work, you need to carefully consider your starting point. This branching pattern was popularized by the 2010 blog post describing what is now referred to as the Gitflow Branching Model.

The advantage of the scheduled release is that you always have a safe version of the code you can make a few quick changes to and deploy; the disadvantage is that you have more branches to manage and keep up to date as changes are made. The more things fall out of sync, the more likely you are to have merge conflicts when you do try to incorporate new work. For example: you need to make a quick security patch to your site, and then you need to roll this patch back into the main development line. If there's been a lot of development work since the last release, you may have code conflicts to deal with when you try to apply the same patch to the newer code.
That approach to branching is in stark contrast to the second style of branching commonly used for continuous deployment. As the name suggests, this style is typically used for systems which are already deployed, as opposed to products with a strict release date. In this style the master branch is always kept in a deployment-ready state. Nothing is considered a hotfix, because all changes are urgent and ready for deployment. Typically, this style of development will have permissions (sometimes referred to as “flippers” or “flags”) which turn off all new functionality exposed by the branch except to privileged users. Then, as the code is tested, the flag is reset to expose the functionality to increasingly more people until it is made public. Etsy, Facebook, and Flickr are all rumored to use this deployment pattern. The exact branching pattern varies a little, but you can get the gist of the pattern from The Dymitruk Model.
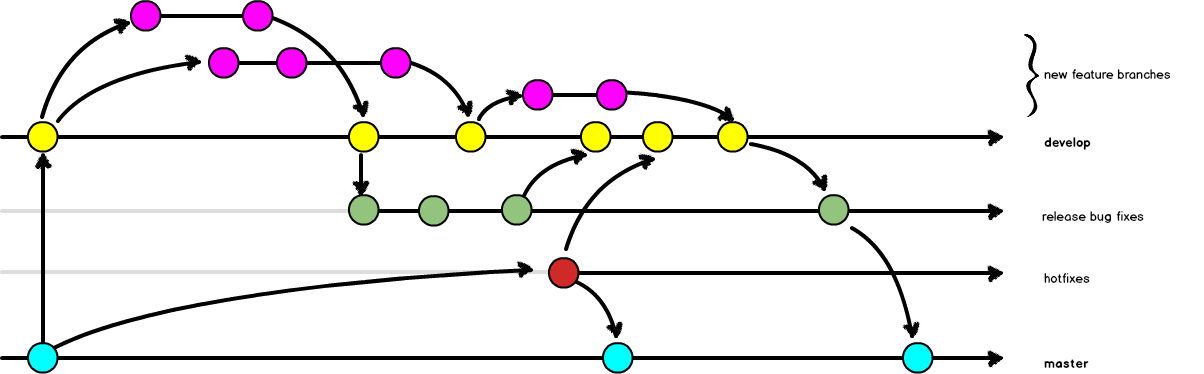
If you hate dealing with merge conflicts, the continuous deployment strategy can look pretty appealing. But this strategy has its own drawbacks as well. When you are using a continuous deployment strategy, it is assumed that the tip of your master branch is always safe to deploy into production. By design, there isn't a space to include a brief pause (of a day or two) for a quality assurance check of the code, and if there was a problem with the deployed code, you would be relying on tags to know when the last safe deployment of the code was. You'd be stuttering your way back through time to try and find a commit which was solid and deployable, with the time pressure of knowing you had broken code on your production server.
The concept of recovery is an important one in source control. Yes, you need to optimize your workflow so that it is easy to move forward, but you must also consider how quickly you can unravel the past and uncover the source of a regression. The two graphs shown were both relatively tidy; in reality, the graphs for your repository may not be as easy to interpret. The tools you use to untangle the past will also dictate how you commit today. (Do you love bisect? You'll want your commits stored in a specific way to take advantage of it.) I wrote about this in more detail at “The Evolution of Social Coding.” The scheduled release model provides more “life lines” to the past, whereas the continuous deployment model is moving constantly forward with smaller, more granular changes over time.
The correct solution for your team probably lies somewhere on the spectrum between the two strategies. To get a sense of how one Drupal team used variations on these two workflows, take a look at the pre-launch and post-launch workflows the Drupalize.Me team used during its upgrade process from Drupal 6 to Drupal 7.
For more information:
Image: "Coucou !" by gadl is licensed under CC BY-SA 2.0